The
ONS Solubility Challenge and the
Reaction Attempts project have now been integrated with code written by
Andrew Lang to the point that recommendations for solvents are just a click away.

The service will then
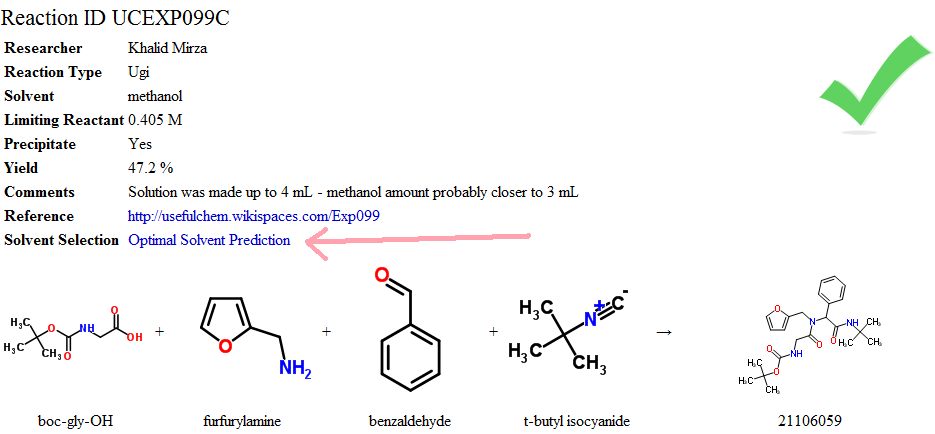
provide a summary of solubility measurements and predictions, organized by the default criteria of minimum 0.3 M solubility of reactants, maximum 0.03 M solubility of the product and maximum solvent boiling point of 100 C. Liquid reactants (or reactants with melting points within 15 C of room temperature) are excluded since these generally have a high enough solubility in most solvents.
In the case of the Ugi reaction in this example, only the solubility of boc-glycine and the product are considered.

The results are color-coded. In this case 14 solvents are coded green, indicating that all criteria were met. The fifteenth solvent is coded yellow, indicating that one of the criteria was not met - in this case the boiling point of 205 C is outside of the limit of 100 C. High boiling point solvents are not optimal for quickly obtaining the product as a dry solid after filtering. This criterion can be changed in the input fields at the top of the page. It is also possible to change the number of times the product is washed there. This will only change the estimated yield, which is based on carrying out the reaction at the concentration of the least soluble reactant, up to 1 M.
Three columns are generated for the product and each reactant. The column on the right is the average of all measurements, as recorded in the
SolubilitiesSum Spreadsheet. The middle column is a solubility prediction based on Abraham descriptors derived from experimental values, as described and used in the
ONS Solubility Challenge book. The column on the left contains predictions from the
Abraham001 model, which is based on calculated molecular descriptors only.
The numbers in bold represent the best solubility value available for each solvent. If a measurement is known, that will be the number used. If no measurement is available, the experimental Abraham descriptor model is used. If neither of these are available the predictions from the Abraham001 model are used by default.
From the list of solvents in the green section we find ethanol and acetonitrile. Both of these solvents were tried (as mixtures with methanol) in the optimization of this reaction (
Bradley et al JoVE 2008) and provided good to intermediate results. THF was found to give low yields for this reaction and it scores at #51 in the yellow section, with a high solubility of the product accounting for the missed criterion.
One should keep in mind that this is just a tool to flag potentially interesting solvents. Common chemical sense needs to be used as well. For example, acetone and butanone are listed in the green section but these are incompatible with the Ugi reaction since they would compete with the aldehyde.
Note that the predictive models are way off in some cases. For example the Abraham001 model dramatically underestimates the solubilities of boc-glycine in the green section, while the measured Abraham descriptor model does much better for these cases. We will prioritize our next solubility measurements to try to improve the models - or at least understand what types of compounds are most likely to yield useful solubility estimates from these models.
In addition to being called from the Reaction Attempts Explorer, the Solvent Selector can be used for any compounds that have ChemSpider IDs. Simply separate the CSIDs with the pipe character:
After modifying the criteria and hitting update, the new criteria are conveniently represented in the URL in this format, making sharing a specific search with anyone easy:
It is even possible to use the service listing just one compound's CSID - this is useful for quickly comparing the measured solubilities with predictions from both models:














 Creative Commons Attribution Share-Alike 2.5 License
Creative Commons Attribution Share-Alike 2.5 License